Introduction:
Given the input of sequences of video frames, can a machine outputs a sequence of words? Such kind of this problem is called video captioning. Current state-of-the-art work is using LSTM. In this paper, we combine CNN and LSTM, to generate sentences describing the video.
Method:
First, we extract the features of input frames, we apply AlexNet, VGG, and GoogleNet to do this work.
Then 2 LSTMs are used in second part. In this picture, the red one models the video sequence, and the green one models the word sequence.
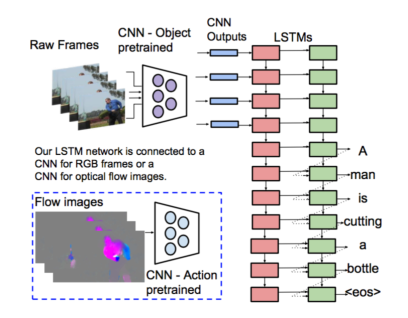 The green one are given text input and video hidden representation, which will predict the next word.
The green one are given text input and video hidden representation, which will predict the next word.The flow images uses optical flow features extracted between frames.
Here we have 3 datasets.

Experiment Result:


沒有留言:
張貼留言