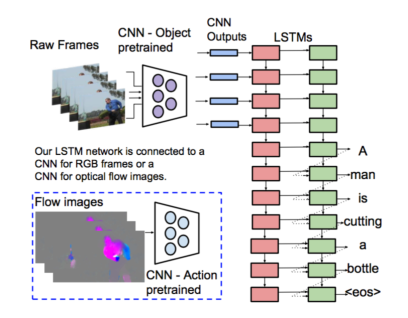
When we are watching an video, we first select objects that we interested, then we see how the objects moving or doing something. Based on this intuition, we proposed two networks to do action recognition, where one is called spatial ConvNet, and the other is called temporal Convnet.
In spatial network, we use single still frame extracted from videos as the input. And in temporal network, we use optical flow displacement fields extracted from consecutive frames as our input. This paper mainly focuses on how they deal with optical flow features.
Optical flow
In high school physics, if an object moves from point a to b, the distance is called displacement. In consecutive 2 frames, we use the following figure to explain:
See the rectangle in (a) and (b), the hands is moving
In (c), the hands moving toward some direction is represented by the optical flow.
In (d), it's horizontal movement part.
In (e), it's vertical movement part.
It is obviously that if we see consecutive frames, we can easily guess what an object is doing, the more frames we see the answer is clearer. Now suppose we watch L consecutive frames, we introduce some stacking method to combine these feature extracted from L frames.
Optical flow stacking
As we see in (d) and (e), for each consecutive 2 frames, we get 2 channels like (d) and (e). Given a static point, we record the displacement vector at that point for each frame. The idea is illustrated here:
Trajectory stacking
Given a point, in frame 0, we record the displacement vector and the stop point. Then in next frame (frame 1), we record the displacement
starting from the stop point at the previous frame. The idea is also illustrated here:
For optical flow stacking, the object may be doing something but stand still, for example, archery competition. And for trajectory stacking, we may want to indicate that a man is walking.
Bi-directional optical flow
For frame 0 to L/2, we do the same thing as the previous two method do. But from frame L/2 to L, we record the reversed displacement vector, do this repeatedly until trace back to frame 0.
Mean flow subtraction
It's simple normalization, the details are not discussed here.
----------------------------------------------------------------------------------------------
Result
For spatial network, we can reach 72.8% only given still images. Adding information from consecutive frames, the result is as follow:
If we watch more frames, the answer we guess could be more precise. The result follows our intuition.